This is the challenge of the week-- how do I get from a 3x3 homography matrix (which relates the plane of the source image to the plane found in the scene image) to an OpenGL modelview transformation matrix so I can start, you know, augmenting reality? The tricky thing is that while I can use the homography to project a 3D point onto the 2D image plane, I need separated rotation and translation vectors to feed OpenGL so it can set the location and orientation of the camera in the scene.
The easy answer seemed to be using OpenCV's
cv::solvePnP() (or its C equivalent,
cvFindExtrinsicCameraParams2()) by inputting four corners of the detected object calculated from the homography. But I'm getting weird memory errors with this function for some reason ("
incorrect checksum for freed object - object was probably modified after being freed.
*** set a breakpoint in malloc_error_break to debug but setting a breakpoint on malloc_error_break didn't really help, and it isn't an Objective-C object giving me trouble, so NSZombiesEnabled won't be any help, etc etc arghhh....) AND it looks like it's possible to decompose a homography matrix into rotation and translation vectors which is all I really need (as long as I have the camera intrinsic matrix, which I found in the
last post). solvePnP looks useful if I wanted to do pose estimation from a 3D structure, but I'm sticking to planes for now as a first step. OpenCV's solvePnP() doesn't look like it has an option to use RANSAC which seems important if many points are likely to be outliers-- an assumption that the Ferns-based matcher relies upon.
Now to figure out the homography decomposition... There are
some equations here and
some code here. I wish this were built into OpenCV. I will update as I find out more.
Update 1: The code found
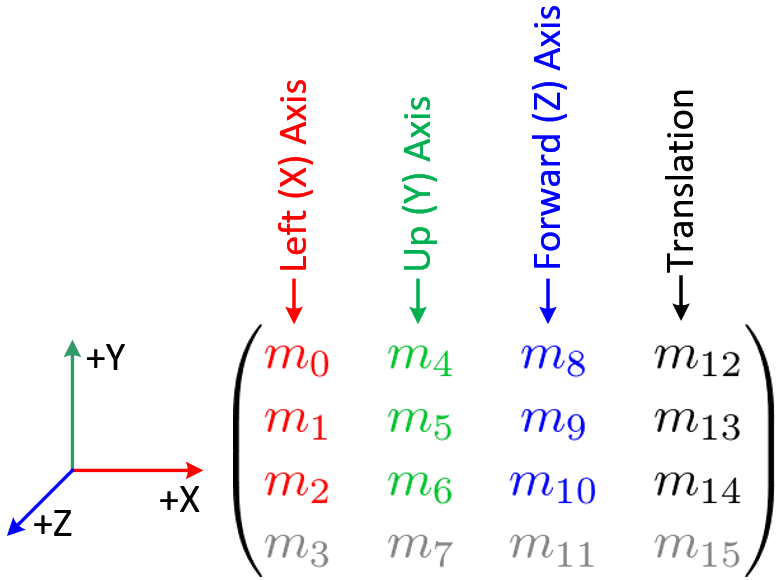
here was helpful. I translated it to C++ and used the OpenCV matrix libraries, so it required a little more work than a copy-and-paste. The 3x3 rotation matrix it produces is made up of the three orthogonal vectors that OpenGL wants (so they imply a rotation, but they're not three Euler angles or anything) which this image shows nicely:
 |
| Breakdown of the OpenGL modelview matrix (via) |
The translation vector seems to be translating correctly as I move the camera around, but I'm not sure how it's scaled. Values seem to be in the +/- 1.0 range, so maybe they are in screen widths? Certainly they aren't pixels. Maybe if I actually understood what was going on I'd know better... Well, time to set up OpenGL ES rendering and try this out.
Update 2: Forgot for a minute that OpenGL's fixed pipeline requires two transformation matrices: a modelview matrix (which I figure out above, based on the camera's EXtrinsic properties) and a projection matrix (which is based on the camera's INtrinsic properties).
These resources might be helpful in getting the projection matrix.
Update 3: Ok, got it figured out. It's not pretty, but it works. I think I came across the same thing as
this guy. Basically I needed to switch the sign on
four out of nine elements of the modelview rotation matrix and two of the three components of the translation vector. The magnitudes were correct, but it was rotating backwards in the z-axis and translating backwards in the x- and y- axes. This was extremely frustrating. So, I hope the code after the jump helps someone else out...